At TheHealthBoard, we're committed to delivering accurate, trustworthy information. Our expert-authored content is rigorously fact-checked and sourced from credible authorities. Discover how we uphold the highest standards in providing you with reliable knowledge.
What is the Stroop Effect?
 Mary McMahon
Mary McMahon
Mary McMahon
Mary McMahon
The Stroop effect is a demonstration of the phenomenon that the brain's reaction time slows down when it has to deal with conflicting information. This slowed reaction time happens because of interference, or a processing delay caused by competing or incompatible functions in the brain. The effect became widely known after John Ridley Stroop, an American psychologist, published a paper on it in 1935, but it had been studied by several other researchers before Stroop.

This phenomenon is typically studied with a Stroop test. In this test, a researcher times how long it takes a test taker to say the name of a color printed in gray or black ink. For instance, the person would see the word "blue" printed and then say "blue." The researcher then shows the test taker color names printed in another color — like the word "green" printed in orange ink — and times how long it takes the test taker to say the color that the word is printed in. Most people are much slower and are more likely to make mistakes during the second task than the first one since the second one presents the brain with conflicting information. Stroop's original test was a little different, but many modern Stroop tests are structured in this way.
An example of the second section of a Stroop test might be:
| red | orange | white | green |
| yellow | brown | orange | white |
| blue | purple | black | red |
| brown | green | orange | yellow |
| white | red | purple | green |

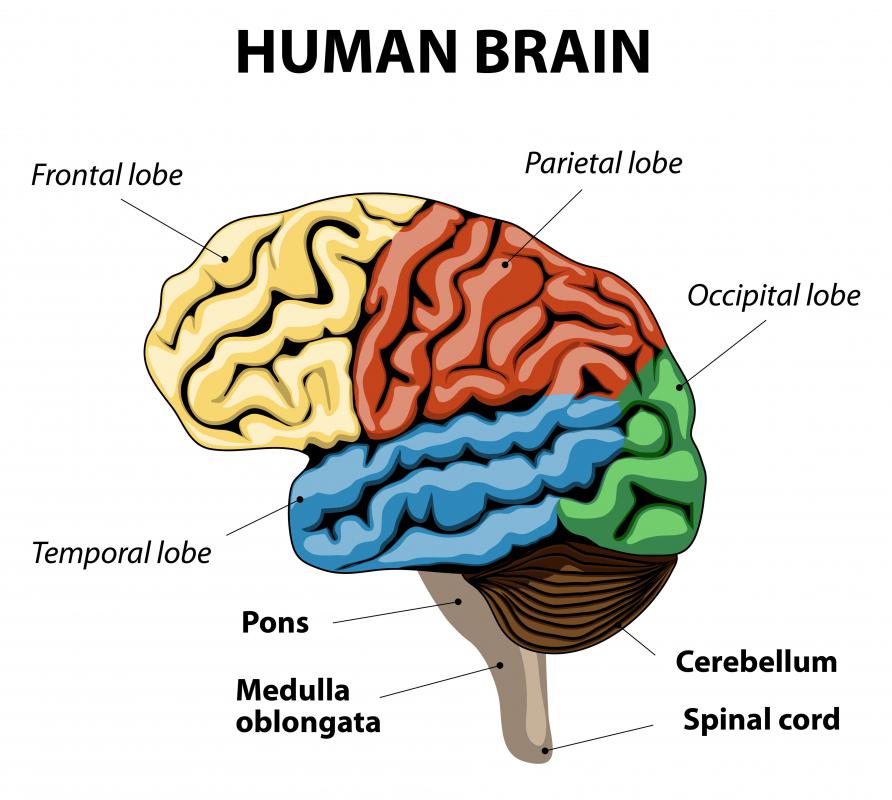
During a Stroop test, two parts of the brain's frontal lobe — the anterior cingulate cortex and dorsolateral prefrontal cortex — come into play. Both are connected to catching errors and resolving conflicts, and the dorsolateral prefrontal cortex is also involved with memory and organization, among other things.
Possible Explanations
There are two main theories used to explain the Stroop effect, but no one final explanation. The theories are:
- Speed of processing theory: the brain reads words faster than it recognizes colors, so there's a lag while the brain recognizes the color.
- Selective attention theory: the brain needs to use more attention to recognize a color than to read a word, so it takes a little longer.
Other theories:
- Automation of reading theory/Automaticity Hypothesis: the brain automatically understands the meaning of words through a long-time habit of reading, but recognizing colors is not an automatic process. When the brain has to name the color, rather than the meaning of the word in the Stroop test it has to override its initial impulse of automatically reading the word rather so that it can recognize its color.
- Bottleneck theory: the brain analyzes most streams of information unconsciously through automatic processes that are hard to control. Processes like color recognition require the brain's attention, but the unconscious processes can disturb that attention, which accounts for the delay.
- Parallel distributed processing theory: as the brain analyzes information, it builds up specific pathways for doing each task. Some pathways, like reading, are stronger than others, like naming colors. So when two pathways are activated simultaneously in the Stroop test, interference occurs between the stronger “reading” path and the weaker “color naming” path.
Uses of the Stroop Effect

The Stroop effect is used in variations of Stroop tests to measure many different things, including how well a person's selective attention works and his or her brain's processing speed. It is also used as part of a group of tests for a person's executive processing, which is basically how good one part of the brain is at managing the other parts. A researcher might also give a Stroop test to a person while also giving him or her a brain scan to see what parts of the brain are involved in things like color recognition or managing interference as a way to study the brain. Tests like this can also shed light on how people would handle interference in other situations, for instance, while texting and driving.

Stroop tests are also used as tools for screening people and diagnosing certain mental problems, including dementia, schizophrenia, brain damage after a stroke, and Attention Deficit Hyperactivity Disorder (ADHD). This can help doctors test certain aspects of how a patient's brain is functioning, particularly aspects related to attention and focusing. For instance, schizophrenics tend to show more interference when taking Stroop tests than those without schizophrenia because that condition makes it hard for the brain to focus and filter some types of information.
Variations on the Stroop Effect

This effect isn't limited to just colors; it has also been shown to have an effect in tests where the words are turned upside down, or at odd angles. Other Stroop tests are based around emotions. For instance, a researcher might show a person cards with words like "depression," "war," and "pain" mixed in with more neutral words like "watch," "doorknob," and "box". Just like in a normal Stroop test, the words are colored and the test taker is supposed to name the color. The researcher then times the test taker to see if the test taker said the sad words faster or slower than the neutral words.
There is also a phenomenon called the reverse Stroop effect, where test takers are shown a page with a black square with a mismatching colored word in the middle — for instance, the word "blue" written in the color red — with four smaller colored squares in the corners. One square would be colored red, one square would be blue, and the two others would be other colors. Experiments show that if the test takers are asked to point to the color box of the written color, blue, they have a delay just as though they were taking a classic Stroop test in which they were supposed to say the shown color of the word, in this case, red.
Additional Resources:
http://psychclassics.yorku.ca — Stroop's original paper.
http://snre.umich.edu — More detailed information about the physiology behind this effect with more quizzes.
http://www.rit.edu — Information about alterative theories on the Stroop effect.
http://www.swarthmore.edu — A paper on the reverse Stroop effect.
Mary McMahon
Ever since she began contributing to the site several years ago, Mary has embraced the exciting challenge of being a TheHealthBoard researcher and writer. Mary has a liberal arts degree from Goddard College and spends her free time reading, cooking, and exploring the great outdoors.
Learn more...
Mary McMahon
Ever since she began contributing to the site several years ago, Mary has embraced the exciting challenge of being a TheHealthBoard researcher and writer. Mary has a liberal arts degree from Goddard College and spends her free time reading, cooking, and exploring the great outdoors.
Learn more...AS FEATURED ON:
AS FEATURED ON:

-
![Different parts of the brain respond when confronted with the Stroop test.]() By: Robert VoightDifferent parts of the brain respond when confronted with the Stroop test.
By: Robert VoightDifferent parts of the brain respond when confronted with the Stroop test. -
![Stroop tests can be used to screen for and assess cases of dementia.]() By: riccardo bruniStroop tests can be used to screen for and assess cases of dementia.
By: riccardo bruniStroop tests can be used to screen for and assess cases of dementia. -
![During a Stroop test, two parts of the brain's frontal lobe come into play.]() By: designuaDuring a Stroop test, two parts of the brain's frontal lobe come into play.
By: designuaDuring a Stroop test, two parts of the brain's frontal lobe come into play. -
![Diagnostic Stroop tests can help assess whether a child has attention deficit disorder (ADD).]() By: Ermolaev AlexandrDiagnostic Stroop tests can help assess whether a child has attention deficit disorder (ADD).
By: Ermolaev AlexandrDiagnostic Stroop tests can help assess whether a child has attention deficit disorder (ADD). -
![A Stroop test may be helpful in shedding light on how people would handle interference while texting and walking or driving.]() By: endostockA Stroop test may be helpful in shedding light on how people would handle interference while texting and walking or driving.
By: endostockA Stroop test may be helpful in shedding light on how people would handle interference while texting and walking or driving.




Discussion Comments
You could also do it with numbers, pictures, words in gibberish or foreign languages, shapes, etc., etc. The possibilities are endless!
Good and simple explanations. However, it would have been better if the aim, procedure, findings and conclusions of the study were mentioned, which can back up the arguments in this blog because at some stages the writing was not convenient without knowing the actual elements of the study! Anyhow again, good post.
I'm using it for my IB internal psychology assessment! IB students! This one is quite easy to conduct and the results are nice to analyze later!
We're using this for a science experiment.
I have seen that (the color thing) done before and I have never been able to accurately name the colors. I never knew that it was an actual experiment. Great information!
Great thanks! Now i understand
Post your comments